이미지맥스는 OCR을 이용해 문자를 인식하는 기능을 내장하고있습니다.
설정만 잘해주면 유용하게 써먹을수 있지만 어느정도 한계도 존재합니다.
이번에는 숫자사이에 특수문자(콤마, 소수점, 슬래쉬) 등이 있을 경우 대처 할수있는 방법을 알아봅니다.
1. 소수점이 있는 경우

다음과 같은 숫자를 OCR을 이용하여 읽어오고자 합니다.
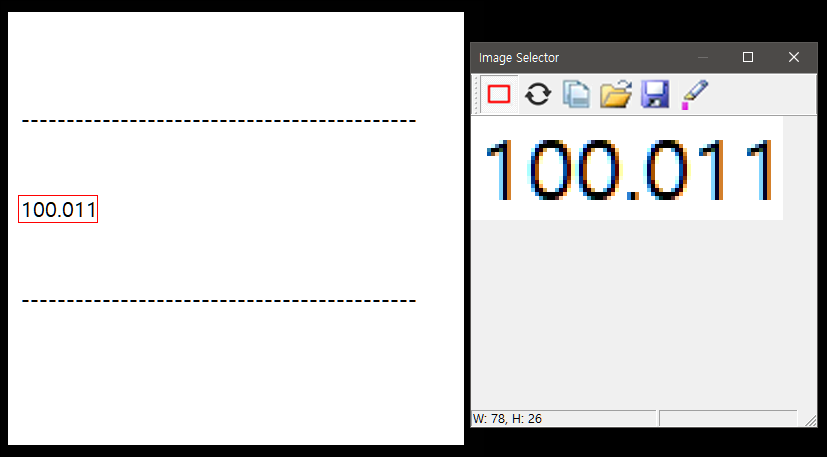

평소에 하듯이 숫자를 OCR 영역으로 지정하여 읽어보니 소숫점을 인식 못하고 100011 로 인식해버리는군요.
이로 인해 원래 숫자보다 너무 큰 숫자가 되어버렸습니다.
이런경우 어떻게 해야 좋을지 고민해봅니다.
[방법1] 특수문자를 인식하기위해 한글, 영문을 함께 체크한다.

숫자만 체크할 경우 콤마(,), 소숫점(.), 슬래쉬(/) 등을 인식할수 없습니다.
대부분의 경우는 한글, 영문을 함께 체크 함으로써 해결이 되는 경우가 많습니다.
단, 이때 OCR로 읽은 데이터는 숫자(number) 타입이 아니라 문자열(string) 타입이므로 tonumber() 함수를 이용하여 숫자형태로 변환을 해주어야합니다.
-- 문자열 타입 데이터를 숫자 타입으로
num = tonumber(NUM_OCR)
[방법2] 구분자를 이미지 인식하여 찾은 좌표 기준 정수부(좌측) 과 소수부(우측) 영역을 연산하여 OCR 인식하기
두번째 방법은 정수부분을 따로 OCR로 읽고, 소수점 부분을 OCR로 따로 읽은뒤 그 둘을 합치는 방법입니다.
step1. 소수점 이미지 캡쳐
이를 위해 가운데에 위치한 소수점을 이미지서치하여 좌표를 알아낼 필요가 있습니다.
소수점의 좌표를 기준으로 좌측숫자의 ROI영역, 우측숫자의 ROI영역을 연산해야하기 때문입니다.
이를 위해 우선 숫자 사이에 있는 소수점을 이미지를 캡쳐하고, ROI를 숫자 영역 전체로 해줍니다.




잘 인식되는지 테스트해봅니다.
잘 찾아지네요. 좌표도 (50, 203) 으로 잘 찾아지는것을 알수있네요.
실제 앱에서는 보다 복잡한 이미지나 색조합, 폰트들로 인해 변수가 생길수 있으니 해당 상황에서도 콤마같은 구분점을 잘 찾을수 있도록 세팅하는것이 중요합니다.
step2. 정수 부분 OCR용 이미지 캡쳐
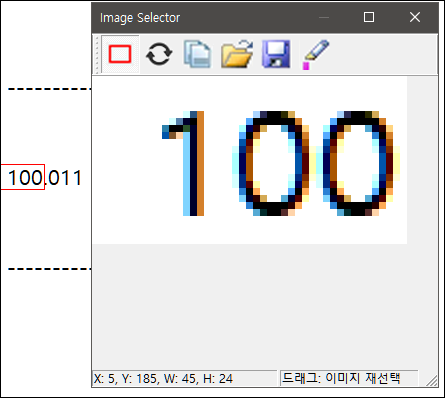
정수부분의 숫자를 OCR 인식할 이미지를 캡쳐합니다.
숫자가 충분히 정확하게 읽어질때까지 OCR 설정을 맞추어줍시다.
step3. 소숫점 부분 OCR용 이미지 캡쳐
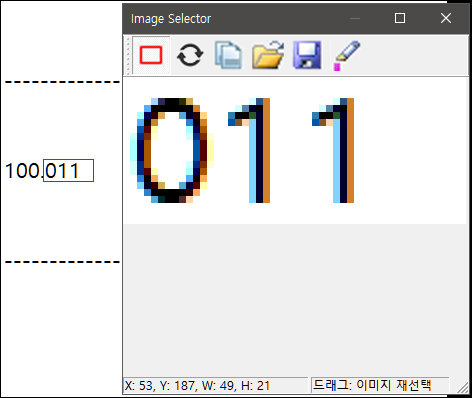
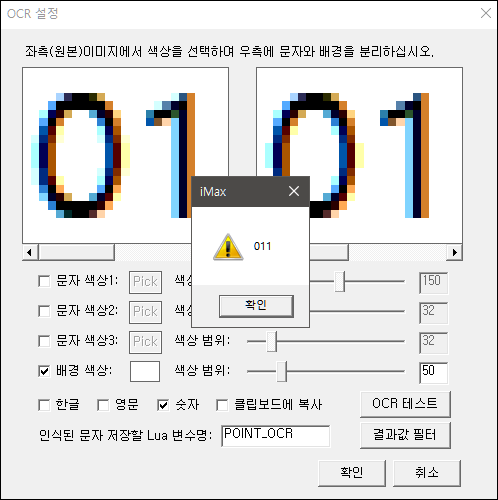
정수부분을 완료했다면 소숫점 부분도 마찮가지로 설정합니다.
단, 011 을 숫자 타입으로 변수에 저장하면 011이 아닌 11로 저장이 되어버립니다.
그렇게 되면 0.011이 되어야할 숫자가 0.11 이 되어버리는 참사가 기다리고 있습니다.
이를 극복하기 위해 한글, 혹은 영문을 체크하여 문자열 타입으로 011이 변수에 저장될수 있도록 해주는게 포인트입니다.

반드시 소숫점 OCR 이미지는 영문이나 한글을 함께 체크하여 문자열로 변수에 저장될수 있도록 합니다.
step4. 소수점 이미지 서치 및 정수, 소수 ROI 영역 연산 스크립트 추가
이미지를 잘 만들었다면 이제 스크립트 코드를 추가할 차례입니다.
소수점의 이미지를 찾은 좌표를 이용하여 좌측에 위치한 정수부와 우측에 위치한 소숫점영역의 ROI를 연산했습니다.
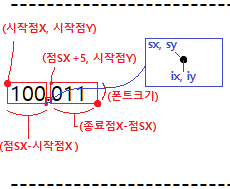
좌측: 정수부의 ROI = {시작점X, 시작점Y, 소숫점sx - 시작점X, 폰트크기}
우측: 소수부의 ROI = {소숫점sx + 5, 시작점Y, 종료점X - 소수점sx, 폰트크기}
그림과 같이 연산한 결과로 연산합니다.
시작점은 숫자가 시작하는 지점, 종료점은 숫자가 끝나는 지점의 좌표를 확인하여 작성합니다.

시작점 좌표는 정수부 OCR 이미지의 좌표를 참조한다면 쉽게 알수있습니다.
정수부 OCR이미지의 시작좌표인 (3, 185) 를 시작 좌표로 설정하겠습니다.
마찮가지로 폰트의 높이는 이미지의 높이 사이즈인 24로 지정합니다.

종료점은 소수점의 이미지의 시작좌표와 이미지 폭을 더하면 계산이 됩니다.
53 + 49 하니 102네요. 약간의 더 여유를 주어 110 정도 좌표를 종료좌표로 기입합니다.
물론 숫자가 가변하여 더 긴 숫자가 올수도 있다면 종료점 좌표를 보다 큰값으로 설정하면 될것입니다.
-- 숫자가 시작점과 종료점, 폰트의 높이 사이즈
local START_X, START_Y = 3, 185
local END_X = 110
local FONT_HEIGHT = 25
-- 수치 중앙 구분자(콤마, 슬래쉬등) 이미지서치
ret, acc, ix, iy, sx, sy = ImageSearch('소숫점')
-- 중앙 구문자 기준 좌측 ROI영역 좌표 생성, 정수OCR 서치
roi = {START_X, START_Y, sx - START_X , FONT_HEIGHT}
SetImageROI('정수_ocr', roi)
ImageSearch('정수_ocr')
print(string.format('정수: %s, 타입: %s', NUM_OCR, type(NUM_OCR)))
-- 중앙 구분자 기준 우측 ROI영역 좌표 연산, 소수OCR 서치
roi = {sx + 5, START_Y, END_X - sx, FONT_HEIGHT}
SetImageROI('소수_ocr', roi)
ImageSearch('소수_ocr')
print(string.format('소수: %s, 타입: %s', POINT_OCR, type(POINT_OCR)))
여기까지 작성한 스크립트를 실행해 봅니다.
잘 읽는듯 합니다.
step5. 데이터 연산
print로 찍은 결과에서 알수 있듯이 정수부는 number 숫자형 데이터 타입을 가지고 있고
소수부는 string으로 문자열 타입을 가지고 있습니다.
그러므로 소수점 부분을 number 형태로 타입을 변경해주어야 더하기 연산이 가능하겠네요.
타입을 변경하는김에 0.011 같이 소숫점 형태로 값도 변경을 해줘봅시다.
011을 0.011 로 연산하기 위해선 1000을 나눠주면 될것입니다. 1000은 다들 아시다시피 10의 3승이죠.
문자열 011의 길이는 3입니다. 그러면 10의 문자의길이 만큼 제곱을 한 값을 나눠준다면 소수점 형태로 값을 바꿀수 있다는 결론에 도달합니다.
자 여기까지 왔으면 이제 끝났네요.
이제 정수값과 연산을 통해 구한 소수값을 더하기만 하면 결과입니다.
그럼 이제 구현해봅니다.
-- 소수부 OCR 데이터의 길이를 변수 len 으로 반환
len = POINT_OCR:len()
print(len)
--> 3
-- 소수점 OCR 데이터를 number 타입을 변경후 10^문자길이 만큼 나누기
point = tonumber(POINT_OCR) / (10^len)
print(point)
--> 0.011 (11 / (10^3) 연산 결과)
-- 정수부 OCR 데이터를 number 타입으로 저장 (이미 타입이 number 이므로 생략하여도 무방)
num = tonumber(NUM_OCR)
print(num)
--> 100
-- 결과 : 정수와 소수 더하기
result = num + point -- 정수부 + 소수부
print(result)
--> 100.011
< 결과 >

잘 동작하는것 같습니다.
여기에 테스트 진행하면서 상황에 맞는 예외처리를 더 추가한다면 더더욱이 좋은 결과를 낼수 있을것입니다.
< 전체 코드 >
-- 중앙 구분자(콤마, 소숫점, 슬래쉬) 등을 찾아 좌/우 ROI영역을 연산하여 OCR 인식
local START_X, START_Y = 3, 185
local END_X = 110
local FONT_HEIGHT = 25
-- 수치 중앙 구분자(콤마, 슬래쉬등) 이미지서치
ret, acc, ix, iy, sx, sy = ImageSearch('소숫점')
-- 중앙 구문자 기준 좌측 ROI영역 좌표 생성, 정수OCR 서치
roi = {START_X, START_Y, sx - START_X , FONT_HEIGHT}
SetImageROI('정수_ocr', roi)
ImageSearch('정수_ocr')
print(string.format('정수: %s, 타입: %s', NUM_OCR, type(NUM_OCR)))
-- 중앙 구분자 기준 우측 ROI영역 좌표 연산, 소수OCR 서치
roi = {sx + 5, START_Y, END_X - sx, FONT_HEIGHT}
SetImageROI('소수_ocr', roi)
ImageSearch('소수_ocr')
len = POINT_OCR:len()
print(string.format('소수: %s, 타입: %s, 길이:%s', POINT_OCR, type(POINT_OCR), len))
-- 문자열 OCR 데이터 넘버로 타입 변경
num = tonumber(NUM_OCR)
point = tonumber(POINT_OCR) / (10^len) -- 숫자 데이터 나눠 소수점화 (ex: 001 -> 1 / 10^3 = 0.001)
result = num + point -- 정수부 + 소수부
print('==================================================')
print(string.format('결과: %f + %f = %f', num, point, result))
print('==================================================')
콤마, 슬래쉬, 소숫점 모두 대응이 가능합니다!
'이미지맥스 그리고 루아(lua) > [응용] 보다 효율적인 사용법' 카테고리의 다른 글
| [이미지맥스] 인식 화면의 영역을 지정하여 변화율 비교하기 (객체지향) (0) | 2022.03.26 |
|---|---|
| [이미지맥스] 내장함수 GetImageROI()를 활용하여 인식화면의 사이즈, 모니터의 해상도를 확인하는 방법 (0) | 2022.03.18 |
| [이미지맥스] 지정영역을 자동으로 분할한 ROI 테이블 만들기 makeRoi() (0) | 2022.02.19 |
| [이미지맥스] 인식 화면의 정지 여부 (앱동작정지) 를 검출하는 방법 (4) | 2021.07.10 |
| [이미지맥스] 앱플레이어 hwnd 윈도우핸들 취득 방법 FindWindow(), FindWindowEx(), PostMessage(), SendMessage(), WM_MESSAGE (0) | 2021.07.10 |



